
دیتاساینتیست آینده: 5 مهارتی که برای موفقیت به آن نیاز دارید

در عصر دیجیتال امروزی، به دادهها لقب «نفت جدید» دادهاند. دادهها قدرت تصمیمگیری و نوآوری را هدایت میکنند و آینده صنایع را در سراسر جهان شکل میدهد. از مراقبتهای بهداشتی و معاملهگری مالی گرفته تا خرده فروشی و سرگرمی، سازمانها از دادهها برای به دست آوردن مزیت رقابتی، بهینهسازی عملیات و ارائه تجربیات شخصی به مشتریان استفاده میکنند. در قلب این تحول علم داده است، یک حوزه چند رشتهای که تجزیه و تحلیل آماری، ماشین لرنینگ، برنامهنویسی و دانش دامنه را برای استخراج بینش عملی از دادهها ترکیب میکند.
علم داده به عنوان یکی از امیدبخشترین و پرسودترین مشاغل قرن بیست و یکم شناخته میشود. طبق آمار اداره آمار کار ایالات متحده، پیشبینی میشود که تقاضا برای دانشمندان داده از سال 2021 تا 2031 به میزان 36 درصد افزایش یابد که بسیار بیشتر از میانگین نرخ رشد سایر مشاغل است. این افزایش با رشد تصاعدی دادهها، پیشرفت در هوش مصنوعی (AI) و اتکای فزاینده به تصمیمگیری مبتنی بر داده تقویت خواهد شد.
کسبوکارها دیگر بر اساس شهود یا احساسات درونی تصمیم نمیگیرند. در عوض، آنها به دانشمندان داده روی میآورند تا مقادیر زیادی از دادههای ساختاریافته و بدون ساختار را تجزیه و تحلیل کنند، الگوها را کشف کنند و روندهای آینده را پیشبینی کنند. به عنوان مثال، نتفلیکس از علم داده برای توصیه محتوای شخصیشده به کاربران خود استفاده میکند، در همین حال که ارائهدهندگان مراقبتهای بهداشتی از تجزیه و تحلیل پیشبینی برای بهبود نتایج بیمار استفاده میکنند. در مقیاس وسیعتر، علم داده با فعال کردن سیاستگذاری مبتنی بر شواهد به چالشهای اجتماعی، مانند تغییرات آبوهوایی و سلامت عمومی، پرداخته است.
با این حال، با پیشرفت این زمینه، انتظارات از دانشمندان داده نیز افزایش مییابد. دانشمند داده آینده باید دارای مجموعه مهارتهای متنوعی باشد که فراتر از تخصص فنی است. آنها باید در حل مسئله، ارتباطات و همکاری ماهر باشند و در عین حال با فناوریها و روشهای نوظهور آشنا باشند. در این پست، پنج مهارت ضروری که علاقهمندان به علم داده برای موفقیت در این زمینه پویا و همیشه در حال تغییر به آن نیاز دارند را بررسی خواهیم کرد.

مهارت 1: تجزیه و تحلیل آماری پیشرفته
چرا تحلیل آماری اهمیت دارد؟
هسته مرکزی علم داده تجزیه و تحلیل آماری است. تجزیه و تحلیل آماری است که بینشهای مبتنی بر داده را میسازد. روشهای آماری دانشمندان داده را قادر میسازد تا دادهها را خلاصه کنند، روندها را شناسایی کنند و بر اساس دادههای نمونه درباره جامعهها استنتاج کنند. چه آزمون A/B برای کمپین های بازاریابی باشد یا ساخت مدلهای پیش بینی، تجزیه و تحلیل آماری ضروری است.
به عنوان مثال، یک شرکت خرده فروشی را در نظر بگیرید که می خواهد استراتژی قیمت گذاری خود را بهینه کند. با تجزیه و تحلیل داده های فروش تاریخی با استفاده از تحلیل رگرسیون، شرکت میتواند تعیین کند که تغییرات قیمت چگونه بر تقاضا تأثیر میگذارد. به طور مشابه، در مراقبتهای بهداشتی، از تکنیکهای آماری مانند آزمون فرضیه برای ارزیابی اثربخشی درمانهای جدید استفاده میشود.
مفاهیم کلیدی آماری برای دانشمندان داده
آمار توصیفی: آمار توصیفی شاخهای از آمار است که بر خلاصه کردن و توصیف ویژگیهای اصلی یک مجموعه داده تمرکز دارد. خلاصههای سادهای در مورد نمونه و معیارها ارائه میکند، و راهی سریع و معنادار برای درک دادهها بدون انجام هرگونه استنتاج یا پیشبینی در مورد جمعیت بزرگتر ارائه میدهد. اساساً، آمار توصیفی به سادهسازی حجم زیادی از دادهها به روشی معقول کمک میکند.
آمار استنباطی: آمار استنباطی شاخهای از آمار است که به ما امکان میدهد بر اساس نمونهای از دادهها، پیشبینی، استنباط یا تعمیم در مورد یک جامعه انجام دهیم. برخلاف آمار توصیفی که ویژگیهای یک مجموعه داده را خلاصه میکند، آمار استنباطی از دادههای نمونه برای نتیجهگیری در مورد جمعیت بزرگتری که نمونه از آن استخراج شده است استفاده میکند. آمار استنباطی به ویژه زمانی مفید است که جمع آوری دادهها از کل جمعیت بسیار دشوار و هزینهبر یا غیرممکن باشد.
نظریه احتمال: نظریه احتمال شاخهای از ریاضیات است که به تجزیه و تحلیل پدیدههای تصادفی میپردازد. چارچوبی برای پیشبینی احتمال نتایج مختلف در موقعیتهای نامشخص فراهم میکند. نظریه احتمالات برای بسیاری از زمینه ها از جمله آمار، مالی، مهندسی، فیزیک و ماشین لرنینگ پایه و اساس است. این به ما کمک می کند تا عدم قطعیت را درک و کمیت کنیم و تصمیم گیری آگاهانه را حتی زمانی که نتایج قطعی نیستند ممکن می سازد.
تحلیل رگرسیون: تحلیل رگرسیون یک روش آماری است که برای بررسی رابطه بین یک متغیر وابسته (که غالباً متغیر نتیجه یا پاسخ نامیده می شود) و یک یا چند متغیر مستقل (اغلب متغیرهای پیش بینی کننده یا توضیحی نامیده می شود) استفاده می شود. هدف تحلیل رگرسیون درک چگونگی تغییر مقدار معمولی متغیر وابسته زمانی است که هر یک از متغیرهای مستقل متغیر است، در حالی که بقیه ثابت نگه داشته میشوند.
تجزیه و تحلیل رگرسیون به طور گستردهای برای پیشبینی و آیندهنگری استفاده می شود، جایی که استفاده از آن همپوشانی قابل توجهی با زمینه ماشین لرنینگ دارد. همچنین برای درک اینکه کدام یک از متغیرهای مستقل به متغیر وابسته مرتبط هستند و برای کشف اشکال این روابط استفاده میشود.
طراحی آزمایشی: به طراحی مجموعهای از آزمایشها به منظور دستیابی به بهینهترین تعداد آزمایش (به انگلیسی: Experiments) در حالی که چندین متغیر در فرایند تبدیل ورودی به خروجی گفته میشود. در آمار طراحی آزمایش معمولاً به طراحی آزمایش کنترلشده گفته میشود هرچند انواع دیگر آزمایشها مانند نظرسنجی و آزمایشهای علوم طبیعی نیز وجود دارند.
کاربردهای عملی
بازاریابی: در بازاریابی، تجزیه و تحلیل آماری پیشرفته برای درک رفتار مصرف کننده، بهینه سازی کمپینها و بهبود تصمیمگیری استفاده میشود. تکنیکهایی مانند تحلیل رگرسیون، تحلیل خوشهای و تحلیل عاملی به تقسیمبندی مشتریان بر اساس جمعیتشناسی، ترجیحات و الگوهای خرید کمک میکنند. برای مثال، کسبوکارها از مدلسازی پیشبینیکننده برای پیشبینی روند فروش، شناسایی مشتریان با ارزش بالا و شخصیسازی استراتژیهای بازاریابی استفاده میکنند. تست A/B که توسط آزمون فرضیه ارائه میشود، به بازاریابان اجازه میدهد تا اثربخشی کمپینهای مختلف را با هم مقایسه کنند، در حالی که تجزیه و تحلیل احساسات بازخورد مشتری، بینشهایی را در مورد درک برند ارائه میدهد. این برنامهها به کسبوکارها این امکان را میدهند که منابع را به طور مؤثر تخصیص دهند، تعامل مشتری را افزایش دهند و رشد درآمد را افزایش دهند.
امور مالی: در امور مالی، تحلیل های آماری پیشرفته نقش مهمی در مدیریت ریسک، استراتژیهای سرمایهگذاری و پیشبینی بازار ایفا میکند. تکنیکهایی مانند تحلیل سریهای زمانی، شبیهسازی مونت کارلو و بهینهسازی پرتفوی به تحلیلگران کمک میکند تا قیمت سهام را پیشبینی کنند، نوسانات بازار را ارزیابی کنند و ریسکهای مالی را مدیریت کنند. به عنوان مثال، مدلهای رگرسیون برای شناسایی عوامل مؤثر بر قیمت داراییها استفاده میشوند، در حالی که آزمون فرضیه استراتژیهای معاملاتی را تأیید میکند. ابزارهای آماری همچنین از مدلهای امتیازدهی اعتباری، سیستمهای تشخیص تقلب و تست استرس برای موسسات مالی پشتیبانی میکنند. با استفاده از این روشها، متخصصان مالی می توانند تصمیمات مبتنی بر داده اتخاذ کنند، ریسکها را به حداقل برسانند و بازده سرمایهگذاری را به حداکثر برسانند.
مراقبت های بهداشتی: در مراقبتهای بهداشتی، تجزیه و تحلیل آماری پیشرفته برای بهبود نتایج بیمار، بهینهسازی درمانها و پیشرفت تحقیقات پزشکی ضروری است. تکنیکهایی مانند تجزیه و تحلیل بقا، رگرسیون لجستیک و آمار بیزی برای تجزیه و تحلیل دادههای کارآزمایی بالینی، پیش بینی پیشرفت بیماری و ارزیابی اثربخشی درمان استفاده میشود. به عنوان مثال، مدلهای آماری به شناسایی عوامل خطر بیماریهای مزمن کمک میکنند و امکان مداخله زودهنگام و پزشکی شخصیسازی شده را فراهم میکنند. در اپیدمیولوژی، روشهایی مانند رگرسیون و تجزیه و تحلیل خوشهای، شیوع بیماریها را دنبال میکنند و مداخلات بهداشت عمومی را ارزیابی میکنند. علاوه بر این، ابزارهای آماری برای تجزیه و تحلیل دادههای بیمار، بهینه سازی عملیات بیمارستان و کاهش هزینه های مراقبت های بهداشتی استفاده می شود. این برنامه ها به تصمیمگیری بهتر، بهبود مراقبت از بیمار و پیشرفت در علم پزشکی کمک میکنند.
چگونه این مهارت را توسعه دهیم؟
دورههای آنلاین: پلتفرم هایی مانند Coursera و edX دوره هایی را در زمینه آمار برای علم داده ارائه می دهند.
کتابها: «آمار عملی برای دانشمندان داده» نوشته پیتر بروس و اندرو بروس یک منبع عالی است.
تمرین: روی مجموعه دادههای دنیای واقعی با استفاده از ابزارهایی مانند Python ، و R کار کنید.
مهارت ۲: ماشین لرنینگ و هوش مصنوعی
نقش ماشین لرنینگ در علم داده
ماشین لرنینگی (ML) زیرمجموعهای از هوش مصنوعی است که بر ساخت الگوریتمهایی تمرکز دارد که میتوانند از دادهها یاد بگیرند و پیشبینی یا تصمیم بگیرند. این یکی از دگرگونکنندهترین فناوریها در علم داده است که برنامههایی مانند تشخیص تصویر، پردازش زبان طبیعی و سیستمهای توصیه را امکانپذیر میکند.
به عنوان مثال، غولهای تجارت الکترونیک مانند آمازون از الگوریتمهای ML برای توصیه محصولات به کاربران بر اساس سابقه مرور آنها استفاده میکنند. در صنعت خودروسازی، خودروهای خودران برای تفسیر دادههای حسگر و پیمایش ایمن جادهها به ML تکیه میکنند.
تکنیکهای کلیدی ماشین لرنینگ
یادگیری نظارتشده: یادگیری نظارتشده (Supervised learning) نوعی از ماشین لرنینگ (یادگیری ماشین) است که در آن مدل بر روی یک مجموعه داده برچسبگذاری شده آموزش داده میشود. در این زمینه، «برچسب» به این معنی است که هر نمونه آموزشی با یک برچسب خروجی جفت میشود. هدف یادگیری تحت نظارت، یادگیری نقشهبرداری از ورودیها به خروجیها است که به مدل اجازه میدهد روی دادههای جدید و نادیده پیشبینی کند.
یادگیری تحت نظارت یکی از رایجترین و پرکاربردترین رویکردها در ماشین لرنینگ است. در حوزه های مختلفی از جمله تشخیص تصویر، تشخیص گفتار، تشخیص پزشکی و پیش بینی مالی کاربرد دارد.
یادگیری بدون نظارت: یادگیری بدون نظارت (Unsupervised learning) نوعی از ماشین لرنینگ است که در آن مدل بر روی دادهها بدون پاسخهای برچسبدار آموزش داده میشود. هدف شناسایی الگوها، ساختارها یا روابط پنهان در دادهها است. برخلاف یادگیری نظارتشده، که نتایج را بر اساس مثالهای برچسبگذاری شده پیشبینی میکند، یادگیری بدون نظارت ساختار ذاتی دادهها را بررسی میکند و آن را برای کارهایی مانند خوشهبندی، کاهش ابعاد و تشخیص ناهنجاری مفید میسازد. تکنیکهای رایج شامل خوشهبندی k-means، خوشهبندی سلسله مراتبی، تجزیه و تحلیل اجزای اصلی (PCA) و رمزگذارهای خودکار است. یادگیری بدون نظارت به طور گستردهای در بخشبندی بازار، فشردهسازی تصویر، و تجزیه و تحلیل دادههای اکتشافی، که در آن الگوهای دادههای زیربنایی به صراحت شناختهشده نیستند، استفاده میشود.
یادگیری تقویتی: یادگیری تقویتی (Reinforcement learning) نوعی از ماشین لرنینگی است که در آن یک عامل یاد می گیرد که با تعامل با یک محیط برای به حداکثر رساندن پاداش های تجمعی تصمیم بگیرد. برخلاف یادگیری تحت نظارت و بدون نظارت، RL بر یادگیری اقدامات بهینه از طریق آزمون و خطا متمرکز است که توسط سیگنال پاداش هدایت می شود که موفقیت هر عمل را نشان میدهد. عامل محیط را کاوش میکند، اقداماتی را انجام میدهد و بازخوردی را در قالب پاداش یا جریمه دریافت میکند و استراتژی خود را در طول زمان برای دستیابی به اهداف بلندمدت اصلاح میکند. مفاهیم کلیدی شامل تابع پاداش، خط مشی، تابع ارزش، و معاوضه اکتشاف در مقابل بهره برداری است. RL به طور گسترده در برنامه هایی مانند بازی کردن (به عنوان مثال AlphaGo)، روباتیک، وسایل نقلیه خودمختار و سیستم های توصیه استفاده می شود، جایی که تصمیم گیری متوالی بسیار مهم است.
یادگیری عمیق: یادگیری عمیق (Deep learning) زیرمجموعهای از ماشین لرنینگ است که از شبکههای عصبی مصنوعی با لایههای متعدد (از این رو «عمیق») برای مدلسازی الگوهای پیچیده در دادهها استفاده میکند. این شبکهها با الهام از ساختار و عملکرد مغز انسان، به طور خودکار نمایشهای سلسله مراتبی دادهها را یاد میگیرند، از ویژگیهای سطح پایین شروع میشوند و به انتزاعات سطح بالا میروند. یادگیری عمیق در کارهایی که شامل دادههای در مقیاس بزرگ است، مانند تشخیص تصویر و گفتار، پردازش زبان طبیعی و سیستمهای مستقل برتری دارد. معماریهای رایج شامل شبکههای عصبی کانولوشن (CNN) برای دادههای تصویر، شبکههای عصبی تکراری (RNN) برای دادههای متوالی و ترانسفورماتورها برای وظایف زبانی هستند. توانایی آن در مدیریت دادههای بدون ساختار و دستیابی به عملکرد پیشرفته، یادگیری عمیق را به سنگ بنای برنامههای کاربردی هوش مصنوعی مدرن تبدیل کرده است.
روندهای صنعت
AutoML: به فرآیند خودکارسازی توسعه سرتاسر مدلهای ماشین لرنینگی، در دسترس قرار دادن هوش مصنوعی برای افراد غیر متخصص و تسریع فرآیند ساخت مدل اشاره دارد. وظایفی مانند پیش پردازش دادهها، مهندسی ویژگیها، انتخاب مدل، تنظیم هایپرپارامتر و استقرار را خودکار میکند و زمان و تخصص مورد نیاز برای ساخت مدلهای با کارایی بالا را کاهش میدهد. ابزارهایی مانند Google AutoML، H2O.ai، و AutoKeras کاربران را قادر میسازد تا مدلهای سفارشی را بدون دانش فنی عمیق ایجاد کنند. AutoML به ویژه برای کسبوکارهایی که فاقد تیمهای اختصاصی علم داده هستند مفید است و به آنها امکان میدهد از هوش مصنوعی برای کارهایی مانند تقسیم بندی مشتری، تجزیه و تحلیل پیشبینی کننده و تشخیص ناهنجاری استفاده کنند. با دموکراتیزه کردن هوش مصنوعی، AutoML به سازمانها قدرت میدهد تا نوآوری کنند و رقابتی باقی بمانند.
هوش مصنوعی قابل توضیح: هوش مصنوعی توضیحپذیر بر شفافسازی و تفسیرپذیر ساختن مدلهای ماشین لرنینگ تمرکز دارد و کاربران را قادر میسازد تا نحوه تصمیمگیری را درک کنند. از آنجایی که سیستمهای هوش مصنوعی به طور فزایندهای در زمینههای حیاتی مانند مراقبتهای بهداشتی، مالی و عدالت کیفری استفاده میشوند، نیاز به شفافیت و پاسخگویی افزایش یافته است. تکنیکهایی مانند SHAP (توضیحات افزودنی SHapley)، LIME (توضیحات مدل قابل تفسیر محلی) و درختهای تصمیم به کشف استدلال پشت پیشبینیهای مدل کمک میکنند. هوش مصنوعی قابل توضیح برای ایجاد اعتماد، اطمینان از انطباق با مقررات و شناسایی سوگیریها در مدلها بسیار مهم است. به عنوان مثال، در مراقبتهای بهداشتی، XAI میتواند به پزشکان کمک کند تا بفهمند چرا یک سیستم هوش مصنوعی یک درمان خاص را توصیه میکند و اطمینان حاصل کند که تصمیمها هم دقیق و هم از نظر اخلاقی صحیح هستند.
Edge AI: هوش مصنوعی Edge شامل استقرار مدلهای هوش مصنوعی بهجای تکیه بر سیستمهای مبتنی بر ابر است. این رویکرد پردازش دادهها و تصمیمگیری در زمان واقعی را در منبع امکان پذیر میکند، تاخیر، استفاده از پهنای باند و وابستگی به اتصال به اینترنت را کاهش میدهد. هوش مصنوعی Edge در برنامههایی مانند وسایل نقلیه خودران، اتوماسیون صنعتی و دستگاههای خانه هوشمند که پاسخهای فوری بسیار مهم است، بسیار ارزشمند است. به عنوان مثال، در رانندگی خودران، هوش مصنوعی Edge به وسایل نقلیه اجازه میدهد تا دادههای حسگر را به صورت محلی پردازش کنند و بدون انتظار برای سرورهای ابری تصمیمگیری کنند. هوش مصنوعی Edge با نزدیکتر کردن هوش مصنوعی به منبع داده، کارایی، حریم خصوصی و مقیاسپذیری را افزایش میدهد و آن را به یک فعالکننده کلیدی اینترنت اشیا (IoT) و فناوریهای هوشمند تبدیل میکند.
چگونه این مهارت را توسعه دهیم؟
آموزش آنلاین: پلتفرم هایی مانند Kaggle و Fast.ai دوره های آموزشی ML را ارائه می دهند.
پروژه ها: ساخت مدل های ML با استفاده از کتابخانه هایی مانند TensorFlow و Scikit-learn.
گواهینامهها: گواهینامههایی مانند مهندس حرفهای ماشین لرنینگ گوگل را در نظر بگیرید.
مهارت 3: آمادهسازی و پیش پردازش دادهها
اهمیت دادههای تمیز
آمادهسازی داده که به عنوان پاکسازی یا پیش پردازش داده نیز شناخته می شود، فرآیند تبدیل دادههای خام به فرمت قابل استفاده است. تخمین زده می شود که دانشمندان داده 80٪ از زمان خود را صرف این کار میکنند و اهمیت آن را برجسته میکند. دادههای با کیفیت پایین می تواند منجر به مدل های نادرست و بینشهای ناقص شود.
به عنوان مثال، یک مؤسسه مالی که دادههای تراکنش را تجزیه و تحلیل میکند، باید مقادیر گمشده را مدیریت کند، موارد تکراری را حذف کند و قالبها را قبل از ساخت مدلهای تشخیص تقلب استاندارد کند.
قدمهای کلیدی در آمادهسازی دادهها
پاکسازی دادهها: این مرحله اولیه حیاتی شامل شناسایی و تصحیح خطاها، ناسازگاریها و نادرستیها در دادههای خام است. این به مسائلی مانند مقادیر خالی (به عنوان مثال، پر کردن آنها یا حذف سوابق)، ورودیهای تکراری (حذف یا ادغام)، انواع دادههای نادرست (تبدیل رشتهها به اعداد) و دادههای پرت (بررسی مقادیر شدید که به طور قابل توجهی از هنجار منحرف میشوند) میپردازد. هدف بهبود کیفیت دادهها و اطمینان از قابل اعتماد بودن و سازگار بودن دادهها برای تجزیه و تحلیل بیشتر و ساخت مدل است.
تبدیل دادهها: این فرآیند شامل تبدیل دادهها از یک فرمت یا ساختار به دیگری برای مناسب ساختن آن برای تجزیه و تحلیل یا مدلسازی است. تبدیلهای متداول شامل مقیاسبندی ویژگیهای عددی (مانند استانداردسازی یا عادیسازی)، تبدیل متغیرهای طبقهبندی به نمایشهای عددی (بهعنوان مثال، رمزگذاری یکطرف)، و مدیریت توزیعهای اریب (مانند تبدیلهای لگاریتمی) است. تبدیل داده تضمین میکند که دادهها با مفروضات الگوریتمهای انتخابشده مطابقت دارند و میتوانند عملکرد مدل را بهبود بخشند.
یکپارچهسازی دادهها: این مرحله دادهها را از چندین منبع در یک نمای یکپارچه ترکیب میکند. چالشهایی مانند فرمتهای دادههای مختلف، قراردادهای نامگذاری، و ساختارهای داده در منابع مختلف را برطرف میکند. تکنیکهایی مانند نقشهبرداری طرحواره، تطبیق دادهها، و ترکیب دادهها برای ادغام یکپارچه دادهها استفاده میشوند. یکپارچهسازی مؤثر دادهها، دید جامعتر و کلیتری از دادهها را فراهم میکند و امکان تجزیه و تحلیل دقیقتر را فراهم میکند.
مهندسی ویژگی (Feature Engineering): این هنر و علم ایجاد ویژگیهای جدید از ویژگیهای موجود برای بهبود عملکرد مدلهای ماشین لرنینگ است. این شامل درک دامنه اساسی و استفاده از دانش دامنه برای شناسایی ویژگیهای بالقوه آموزنده است که ممکن است به صراحت در دادههای اصلی وجود نداشته باشد. مهندسی ویژگی میتواند شامل ایجاد اصطلاحات تعاملی بین ویژگیها، استخراج ویژگیها از متن یا تصاویر، یا تولید ویژگیهای مبتنی بر زمان باشد. ویژگی های به خوبی مهندسی شده می تواند به طور قابل توجهی دقت و قابلیت تفسیر مدل را افزایش دهد.
ابزار و تکنیکها
کتابخانههای پایتون: پایتون به لطف اکوسیستم غنی از کتابخانهها، نیروگاهی برای بحث و پیش پردازش دادهها است. Pandas کتابخانهای برای دستکاری دادهها است که ابزارهایی برای تمیز کردن، تبدیل و تجزیه و تحلیل دادههای ساخت یافته ارائه میدهد. NumPy با ارائه عملیات عددی کارآمد روی آرایهها، پانداها را تکمیل میکند. برای مدیریت دادههای از دست رفته، Scikit-learn روشهای انتساب را ارائه میدهد، در حالی که OpenRefine برای تمیز کردن مجموعه دادههای نامرتب مفید است. کتابخانههایی مانند Matplotlib و Seaborn به تجسم توزیع دادهها و شناسایی نقاط پرت کمک میکنند. علاوه بر این، PySpark برای پیش پردازش مجموعه دادههای مقیاس بزرگ در محیطهای توزیعشده استفاده میشود. این کتابخانه ها پایتون را به ابزاری ضروری برای دانشمندان داده تبدیل کرده و آنها را قادر میسازد تا دادهها را برای تجزیه و تحلیل و مدلسازی کارآمد آماده کنند.
SQL: SQL (زبان کوئری ساختاریافته) ابزاری اساسی برای کوئری دادهها است، به ویژه هنگام کار با پایگاه داده های رابطه ای. این امکان را به کاربران می دهد تا مستقیماً در یک پایگاه داده پرس و جو کنند، فیلتر کنند، جمع کنند و به مجموعه دادهها بپیوندند، که آن را برای پیش پردازش دادههای ساخت یافته ایدهآل میکند. SQL به ویژه برای مدیریت مجموعه دادههای بزرگی که ممکن است در حافظه جا نشوند مفید است، زیرا عملیات مستقیماً روی سرور پایگاه داده انجام میشود. وظایف متداول شامل تمیز کردن دادهها (به عنوان مثال، حذف موارد تکراری، مدیریت مقادیر NULL)، تبدیل دادهها (به عنوان مثال، چرخش، تغییر شکل)، و استخراج زیر مجموعههای داده برای تجزیه و تحلیل است. ابزارهایی مانند PostgreSQL، MySQL و SQLite به طور گسترده مورد استفاده قرار میگیرند و ادغام SQL با پایتون (از طریق کتابخانههایی مانند SQLAlchemy) یا R (از طریق dplyr) قابلیتهای آن را در گردشهای کاری پیشپردازش دادهها افزایش میدهد.
ابزارهای ایتیال: ابزارهای ETL (Extract, Transform, Load) برای خودکارسازی فرآیند استخراج داده ها از منابع مختلف، تبدیل آن به فرمت قابل استفاده و بارگذاری آن در یک سیستم هدف مانند یک انبار داده طراحی شده اند. ابزارهایی مانند Apache NiFi، Talend و Informatica رابط های کاربرپسند و رابطهای از پیش ساخته شده را برای مدیریت منابع دادههای مختلف، از جمله پایگاههای داده، APIها و ذخیرهسازی ابری ارائه میدهند. این ابزارها وظایف پیشپردازش دادهها مانند پاکسازی دادهها، حذف مجدد و تجمیع را ساده میکنند و در عین حال کیفیت و ثبات دادهها را تضمین میکنند. ابزارهای ETL به ویژه در تنظیمات سازمانی ارزشمند هستند، جایی که حجم زیادی از دادهها از منابع متعدد باید یکپارچه شده و برای تجزیه و تحلیل آماده شوند. آنها سازمان ها را قادر می سازند خطوط لوله داده قوی و مقیاس پذیر ایجاد کنند، تلاش دستی را کاهش داده و کارایی را بهبود می بخشند.
منابع برای یادگیری
- کتاب: «پایتون برای تجزیه و تحلیل دادهها» نوشته وس مک کینی.
- دورهها: دوره Data Cleaning in Python در DataCamp
- تمرین: روی مجموعه داده های پلتفرم هایی مانند Kaggle و UCI Machine Learning Repository کار کنید.
مهارت ۴: ارتباط و داستانسرایی
قدرت داستانسرایی داده
دانشمندان داده باید بتوانند یافتههای خود را به طور موثر به ذینفعان غیر فنی منتقل کنند. این شامل ترجمه تجزیه و تحلیلهای پیچیده به بینشهای روشن و قابل اجرا است. داستان سرایی دادهها تجسم دادهها، روایت و زمینه را ترکیب میکند تا داده ها را مرتبط و قانع کننده کند.
به عنوان مثال، یک دانشمند داده که نتایج تقسیمبندی مشتری را به یک تیم بازاریابی ارائه میکند، ممکن است از تجسمهایی مانند نمودار میلهای و نقشه حرارتی، همراه با روایتی استفاده کند که توضیح میدهد چگونه هر بخش را میتوان هدف قرار داد.
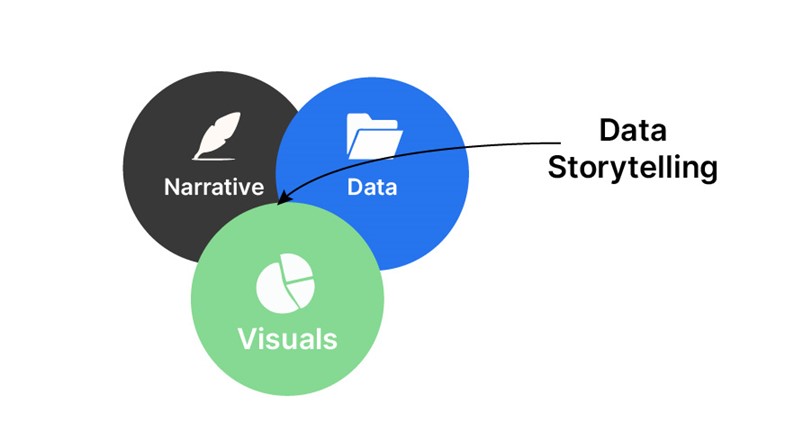
عناصر کلیدی داستانسرایی داده
تصویریسازی: تصویرسازی و تجسم فرآیند نمایش دادهها به صورت گرافیکی برای درک بهتر الگوها، روندها و روابط است. تصویرسازیهای موثر بصری، از نظر بصری جذاب و متناسب با سطح تخصص مخاطب هستند. انواع متداول تجسم عبارتند از:
- نمودارها: نمودارهای میله ای، نمودارهای خطی، نمودارهای پراکنده، و نمودارهای دایره ای برای مقایسه مقادیر یا نشان دادن روندها.
- نقشهها: تجسمهای جغرافیایی برای برجسته کردن الگوهای منطقهای.
- داشبوردها: نمایشگرهای تعاملی که تجسم های متعدد را در یک نمای واحد ادغام میکند.
- اینفوگرافیک: ترکیب تصاویر و متن برای بیان یک داستان به روشی مختصر و جذاب.
چرا مهم است: تجسم به مخاطب کمک میکند تا به سرعت داده های پیچیده را درک کند، بینشهای کلیدی را شناسایی کند و اطلاعات را حفظ کند. ابزارهایی مانند Tableau، Power BI، Matplotlib و Seaborn به طور گسترده ای برای ایجاد تصاویر تاثیرگذار استفاده میشوند.
مثال: یک تیم بازاریابی از یک نمودار خطی استفاده میکند تا نشان دهد که چگونه ترافیک وبسایت در طول زمان افزایش یافته است، همراه با حاشیه نویسی که تأثیر کمپین های خاص را برجسته میکند.
روایت: روایت خط داستانی است که دادهها را به هم پیوند میدهد و مخاطب را از طریق بینشها به شیوهای منطقی و جذاب راهنمایی میکند. یک روایت خوب ساختار روشنی دارد که اغلب از یک چارچوب سه بخشی پیروی میکند:
- شروع: معرفي مشكل يا سؤالي كه به آن پرداخته مي شود.
- میانه: ارائه داده ها و تجزیه و تحلیل، برجسته کردن یافته های کلیدی.
- پایان: با بینشها یا توصیههای عملی پایان دهید.
چرا مهم است: یک روایت قوی زمینه را فراهم میکند، مخاطب را درگیر نگه میدارد و اطمینان میدهد که دادهها به درستی تفسیر میشوند. اعداد خام را به داستانی تبدیل میکند که با مخاطب طنین انداز میشود.
مثال: یک دیتا ساینتیست روایتی را در مورد ریزش مشتریها ارائه میکند که با مشکل (نرخ ریزش بالا) شروع، تجزیه و تحلیل دادهها (شناسایی عوامل کلیدی مانند قیمتگذاری و پشتیبانی مشتری) و پایان دادن با توصیهها (بهبود خدمات مشتری و ارائه تخفیف) تمام میشود.
زمینه: زمینه اطلاعات پس زمینه مورد نیاز برای درک داده ها و اهمیت آن را فراهم می کند. شامل:
- دانش دامنه: توضیح شرایط یا روندهای خاص صنعت.
- منابع دادهها: توضیح اینکه داده ها از کجا آمده اند و چگونه جمع آوری شدهاند.
- محدودیتها: پذیرش هرگونه محدودیت یا عدم قطعیت در دادهها.
- ارتباط: ارتباط دادهها با اهداف یا چالشهای مخاطب.
چرا مهم است: زمینه تضمین میکند که مخاطب متوجه میشود چرا دادهها اهمیت دارند و چگونه با نیازهایشان ارتباط دارند. بدون زمینه، دادهها می توانند به اشتباه تفسیر شوند یا به عنوان نامربوط رد شوند.
مثال: یک تحلیلگر مراقبتهای بهداشتی توضیح میدهد که مجموعه دادههای مربوط به پیامدهای بیمار از یک شبکه بیمارستانی خاص میآید و نشان میدهد که چگونه یافتهها میتوانند استراتژیهای درمانی برای جمعیتهای مشابه را مشخص کنند.
مطالعات موردی
Spotify: از داستان سرایی داده برای به اشتراک گذاشتن آمار شخصی شنیداری پایان سال با کاربران استفاده میکند.
نیویورک تایمز: از تجسم داده ها برای توضیح موضوعات پیچیده مانند نتایج انتخابات استفاده میکند.
چگونه این مهارت را تقویت کنیم؟
- تمرین: یافته های خود را به همسالان یا مربیان ارائه دهید.
- دوره ها: دوره های داستان سرایی را در پلتفرم هایی مانند LinkedIn Learning شرکت کنید.
- بازخورد: به دنبال بازخورد از ذینفعان باشید تا سبک ارتباطی خود را اصلاح کنید.
مهارت 5: تخصص دامنه
چرا دانش دامنه مهم است
در حالی که مهارت های فنی ضروری است، تخصص حوزه چیزی است که دانشمندان داده بزرگ را متمایز می کند. درک صنعت خاصی که در آن کار می کنید به شما امکان می دهد سؤالات درست بپرسید، داده ها را به طور دقیق تفسیر کنید و بینش های مرتبط را ارائه دهید.
به عنوان مثال، یک دانشمند داده در مراقبت های بهداشتی باید اصطلاحات پزشکی و الزامات نظارتی را برای ساخت مدل هایی که پذیرش مجدد بیمار را پیش بینی می کند، درک کند.
نمونههایی از دانش دامنه در عمل
- خرده فروشی: تجزیه و تحلیل الگوهای خرید مشتری برای بهینه سازی موجودی.
- امور مالی: شناسایی تراکنش های تقلبی با استفاده از تشخیص ناهنجاری.
- انرژی: پیش بینی خرابی تجهیزات برای کاهش زمان خرابی.
نحوه ایجاد دانش دامنه
تحقیقات صنعت: از روندها و چالش های صنعت به روز باشید.
همکاری: همکاری نزدیک با کارشناسان حوزه و ذینفعان.
گواهینامه ها: گواهینامه هایی مانند Certified Analytics Professional (CAP) را دنبال کنید.
نتیجهگیری
حوزه علم داده با سرعتی سریع در حال پیشرفت است که به دلیل پیشرفت در فناوری و اهمیت فزاینده تصمیم گیری مبتنی بر داده است. برای پیشرفت در این محیط پویا، دانشمندان مشتاق داده باید مجموعه ای از مهارت های کامل را توسعه دهند که شامل تجزیه و تحلیل آماری پیشرفته، ماشین لرنینگی، کشمکش داده ها، ارتباطات و تخصص حوزه است.
این مهارت ها فقط فنی نیستند. آنها همچنین شامل تفکر انتقادی، خلاقیت و همکاری هستند. با افزایش تقاضا برای دانشمندان داده، کسانی که در یادگیری مستمر و سازگاری سرمایه گذاری می کنند، بهترین موقعیت را برای موفقیت خواهند داشت.
چه به تازگی سفر خود را شروع کرده اید و چه به دنبال پیشرفت شغلی خود هستید، به یاد داشته باشید که علم داده به همان اندازه که در مورد حل مشکلات دنیای واقعی است، در مورد اعداد و ارقام است. چالش ها را بپذیرید، کنجکاو بمانید و هرگز از یادگیری دست نکشید. آینده علم داده روشن است و با مهارت های مناسب می توانید در خط مقدم این حوزه هیجان انگیز باشید.

